Modules
This course is divided into separate modules, each designed to give you a hands-on experience working in teams to reproduce or examine a fundamental result in global change ecology. Each module will also introduce a different type of data and different tooling to handle it, as described in the summaries below. Weekly readings and introductory live-code sessions will provide some necessary background, but real learning will happen only by doing. Workflow and communication are central elements to each module. All work should appear in professional and well documented format using RMarkdown notebooks in the project GitHub repository and pass all automated checks on Travis-CI.
Computing in R
Introduction to programming
In this module, we will focus on programming fundamentals, with applications to biological data. We will also introduce libraries like plyr and dplyr to go over how the tidyverse gang opts to do data manipulation.
Host-virus associations
VIRION
In this module, we will learn how to manipulate and visualize data, using the largest host-virus association database as a learning tool.
Ecological Simulation
memory Simulated data
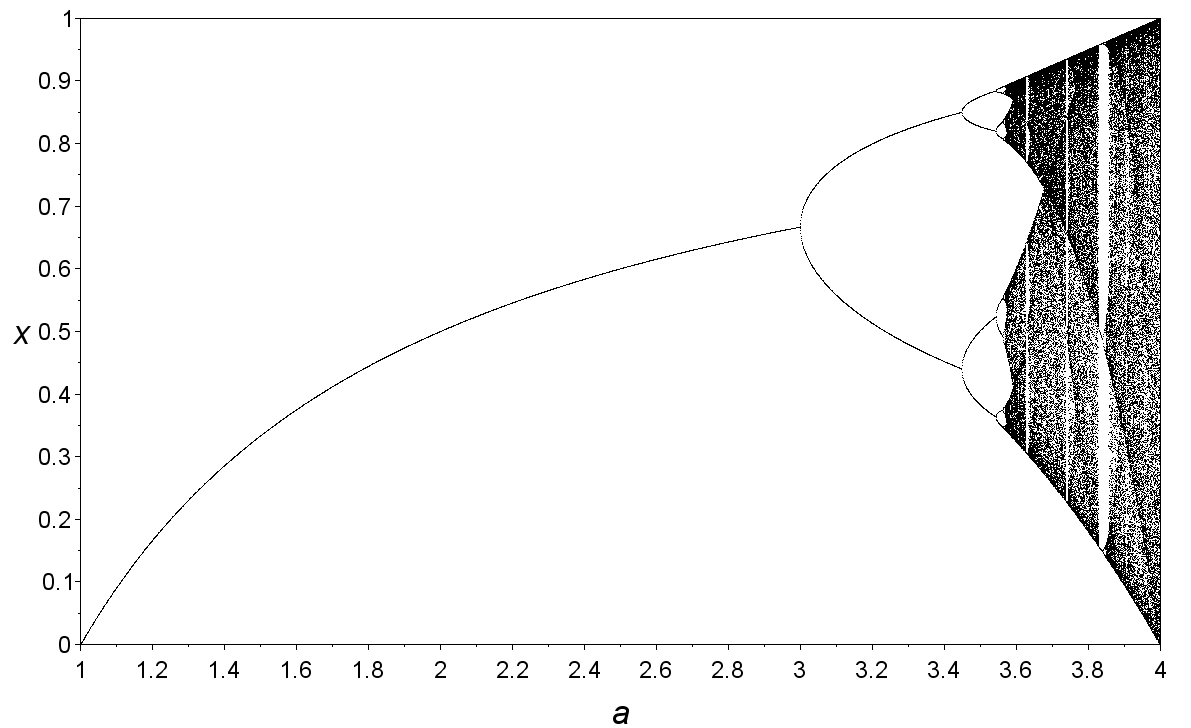
In this module, we will discuss how to simulate biological dynamics to test theory. In doing so, we will go over working with structured data (e.g., lists) and parallelization.
Species distribution modeling
satellite Geospatial data
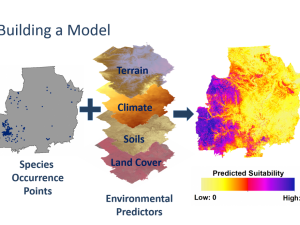
In this module, we will learn how to query APIs, visualize geospatial data, and build predictive models of species geographic distributions.

 From Schell
From Schell